Dari "Trees Always Win" ke Tabular Foundation Model
Kenapa trees selalu menang di data tabular, dan apa yang akhirnya berubah.
Kamu scroll kode Kaggle. Baca tugas akhir kating. Cek paper di internet. Kalau datanya tabel, satu nama muncul di mana-mana: XGBoost.
Baseline yang nggak ada yang mau hadapi. Hampir selalu menang. Kalau kalah pun? Biasanya ke sesama tree-based model.
Deep learning memang luar biasa buat gambar, teks, suara. Tapi data tabular? Ceritanya beda.
Ini bukan mitos. Ada paper “Why do tree-based models still outperform deep learning on typical tabular data?” yang menguji klaim ini secara serius: 45 dataset, berbagai model deep learning terbaru, dibandingkan head-to-head dengan XGBoost dan Random Forest. Hasilnya? Tree-based models masih state-of-the-art, bahkan kalau keunggulan kecepatan training-nya tidak ikut dihitung.
Tapi kenapa bisa begitu? Untuk menjawabnya, kita perlu mundur dulu.
Untuk memahami kenapa trees sulit dikalahkan, kita perlu lihat dulu seperti apa data tabular di dunia nyata, dan kenapa sifatnya yang membuat neural network kesulitan.
Sebagian besar data yang dipakai organisasi berbentuk tabel. Data riwayat pasien di rumah sakit, skor kredit di perbankan, log klik pengguna di platform iklan, data churn pelanggan. Semuanya tabular. Dan isi tiap dataset itu selalu campur: ada kolom numerik, ada yang kategorikal, ada yang biner, dengan skala dan distribusi yang berbeda-beda di tiap kolom.
Masalahnya bukan cuma soal format. Ada yang lebih mendasar: data tabular tidak punya struktur inheren antar kolom. Gambar punya spatial structure, piksel yang berdekatan saling berhubungan. Teks punya sequential structure, urutan kata membentuk makna. Tabular tidak punya itu.
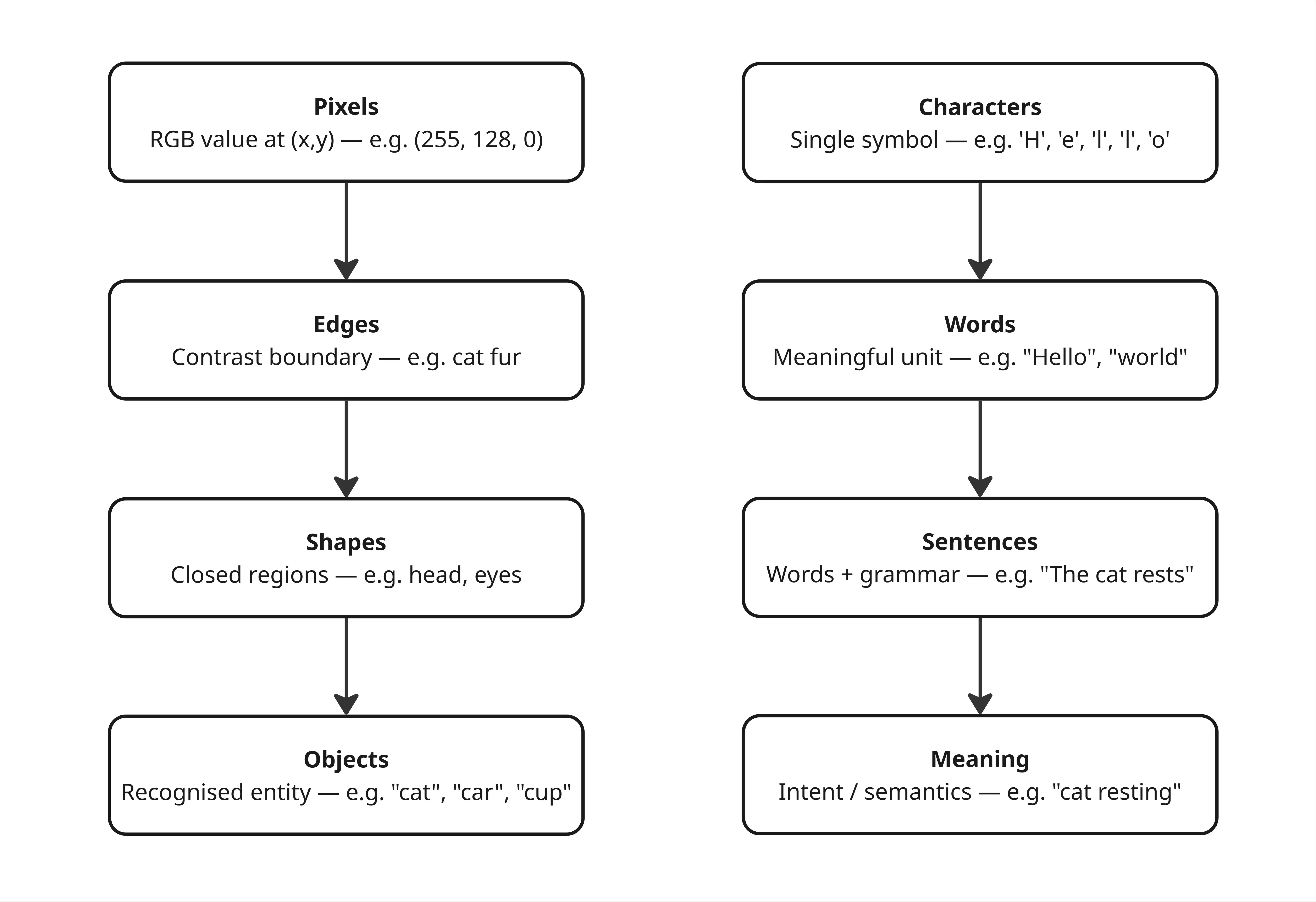
Ini yang dikenal sebagai inductive bias, yaitu asumsi bawaan tentang bentuk data yang membantu model belajar lebih efisien. CNN dibangun di atas asumsi lokalitas spasial. Transformer dibangun di atas asumsi urutan. Keduanya efektif justru karena ada struktur yang bisa dieksploitasi.
Tabular tidak punya inductive bias seperti itu. Kolom ke-3 dan kolom ke-4 tidak punya hubungan posisional yang berarti. Relasi antar fitur harus dipelajari dari nol, tanpa jalan pintas. Itu beban yang berat, terutama kalau datanya tidak banyak.
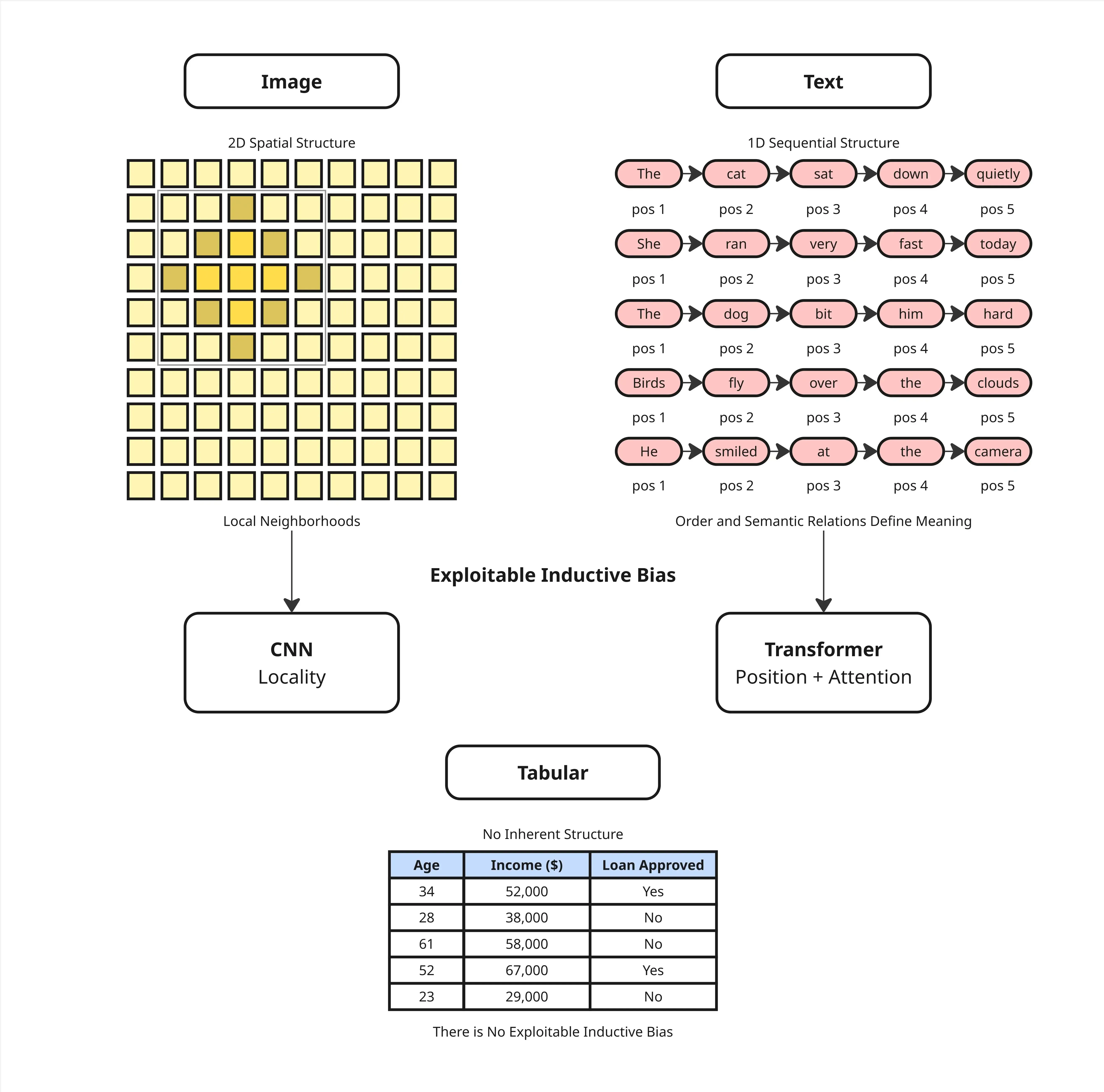
CNN Punya Lokalitas, Transformer Punya Urutan. Tabular Tidak Punya Keduanya.
Belum lagi tantangan praktisnya. Dataset tabular dunia nyata jarang bersih: missing values, noise, kolom yang formatnya campur aduk, ada angka, ada teks, ada tanggal. Dari ratusan fitur yang ada, seringkali hanya sebagian kecil yang benar-benar relevan. Semua itu, mulai dari normalisasi nilai, encoding teks jadi angka, sampai mengisi data kosong, harus dikerjakan manual sebelum model bisa mulai training.
Dan pilihan preprocessing punya dampak nyata. Encoding fitur kategorikal misalnya: kalau pakai one-hot encoding, tabelnya jadi penuh kolom kosong. Kalau pakai ordinal encoding, urutan yang tadinya tidak ada malah jadi implisit. Tidak ada strategi yang selalu benar, dan keputusan kecil di sini bisa ikut terbawa ke prediksi akhir.
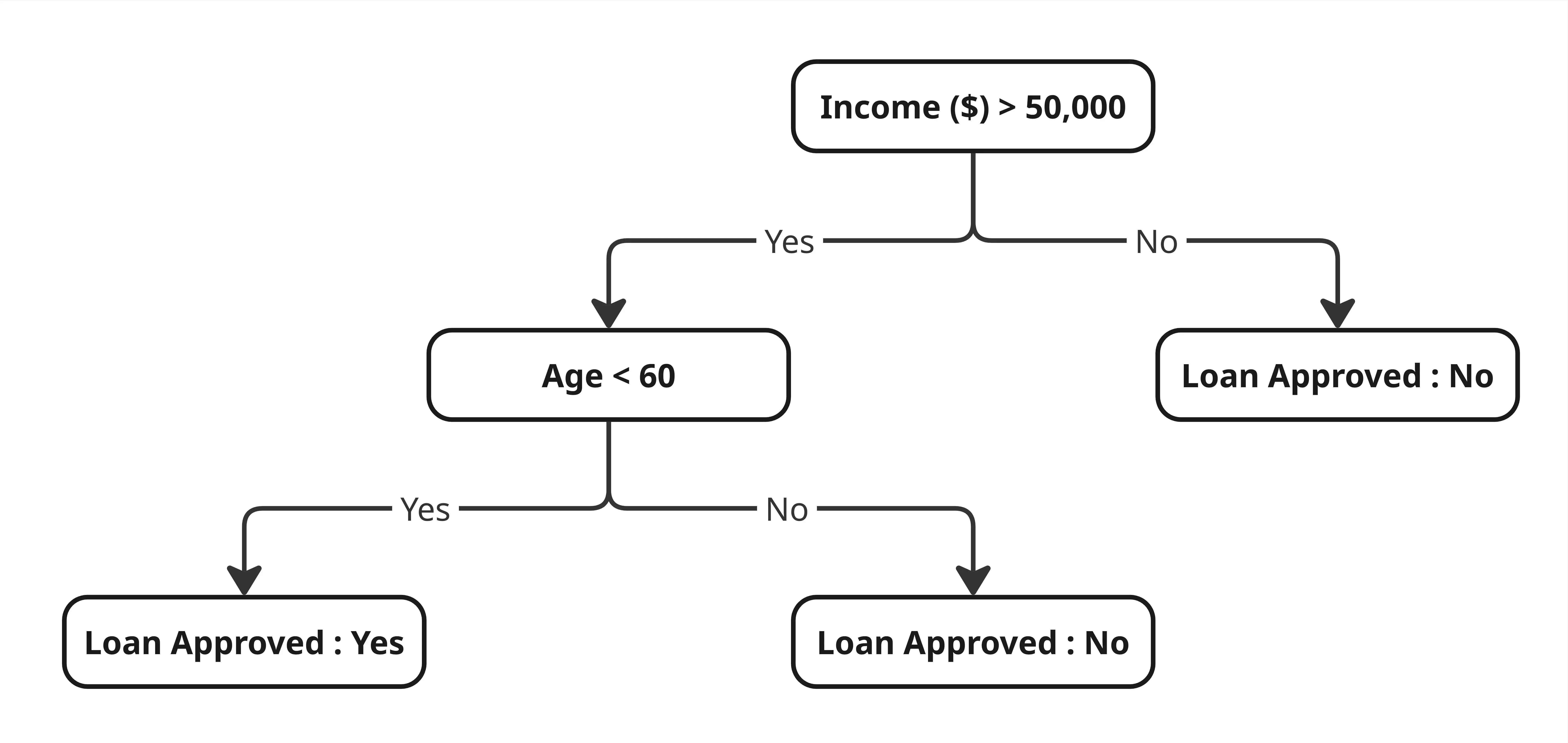
Tree-based models tidak punya masalah seperti itu. Cara mereka bekerja memang cocok dengan karakteristik tabular data: mereka belajar rules. Misalnya: “Kalau pendapatan > 800jt dan usia < 60, kemungkinan kredit disetujui.” Decision tree sangat baik menemukan aturan kondisional seperti ini langsung dari data, tanpa perlu representasi abstrak. Proses splitting-nya otomatis mengabaikan fitur yang tidak informatif. Dari 100 kolom kalau cuma 10 yang relevan, tree fokus ke 10 itu.
XGBoost membawa ini lebih jauh. Tree dibangun secara sekuensial. Setiap tree baru memperbaiki kesalahan tree sebelumnya. Hasilnya model yang akurat dan relatif cepat, tanpa perlu normalisasi, tanpa format khusus, dan secara bawaan tahan terhadap outlier.
Berbagai arsitektur neural network sudah dicoba untuk domain ini: MLP standar, TabNet yang dirancang khusus untuk memilih fitur relevan secara otomatis, sampai FT-Transformer yang mengadaptasi mekanisme attention ke data tabular. Survei “Deep Neural Networks and Tabular Data: A Survey” yang mengevaluasi 11 pendekatan deep learning sampai pada kesimpulan yang sama: gradient-boosted tree ensembles masih lebih unggul, bahkan dengan tuning yang ekstensif.
Neural network butuh struktur yang bisa dieksploitasi. Tabular data tidak punya itu. Tidak heran kalau domain ini dijuluki “the last unconquered castle” untuk deep learning.
Pertanyaannya bukan lagi apakah deep learning kalah di sini. Itu sudah terjawab. Yang belum: apakah ini karena memang tidak mungkin, atau karena pendekatannya yang salah?
Ternyata pendekatannya yang salah. Bukan karena tidak ada arsitektur yang bagus, tapi karena paradigma yang dipakai dari awal kurang tepat.
Untuk memahami kenapa, kita perlu mampir sebentar ke sesuatu yang muncul dari dunia LLM: in-context learning (ICL).
Kamu mungkin sudah familiar. Ketika kamu kasih GPT beberapa contoh input-output di dalam prompt, lalu tanya kasus baru, model langsung bisa menjawab tanpa perlu ditraining ulang. Itu ICL. Model “belajar” langsung dari contoh yang ada di depannya saat itu, tanpa ada parameter yang berubah.
Ini yang bikin ICL berbeda dari supervised learning biasa. Fine-tuning mengubah bobot model, ICL tidak. Model mengamati pola dari contoh di context, lalu membuat prediksi, mirip seperti cara manusia belajar dari analogi. Semuanya terjadi dalam satu kali baca, tidak ada training yang terlibat.
Keunggulan praktisnya langsung terasa: tidak perlu data berlabel dalam jumlah besar, tidak perlu infrastruktur training. Cukup sediakan contoh yang relevan dan model langsung mengikuti polanya.
Tapi yang lebih menarik bukan ICL itu sendiri, melainkan penjelasan di baliknya. Paper “Transformers Can Do Bayesian Inference” berargumen bahwa ICL bisa dipahami sebagai proses Bayesian inference. Ide dasarnya begini: sebelum melihat data apapun, model punya prior, semacam intuisi awal tentang seberapa mungkin berbagai jawaban itu benar. Ketika contoh-contoh masuk, intuisi itu diperbarui jadi posterior: kesimpulan yang sudah mempertimbangkan bukti yang baru saja dilihat.
Model yang ditraining di banyak task berbeda secara implisit membangun intuisi tentang pola umum di balik data, bukan menghafal, tapi memahami. Semakin beragam task yang pernah dilihat, semakin tajam intuisinya. Dan ketika dikasih contoh baru, ia tidak mulai dari nol, tapi langsung menyesuaikan pemahamannya dengan data yang ada.
Ini juga menjelaskan kenapa kemampuan model besar sering terlihat “tiba-tiba muncul”. Bukan karena ada yang magis, tapi karena model itu sudah melihat cukup banyak pola sampai tahu mana yang paling mungkin benar.
Ada batasnya tentu. Kalau tipe data yang dihadapi benar-benar di luar pengalaman model selama training, prediksinya akan meleset. Yang lebih kritis: makin banyak contoh yang dikasih justru makin memperkuat keyakinannya pada jawaban yang salah. Kalau intuisi dasarnya keliru, seluruh kesimpulan yang dibangun di atasnya ikut keliru.
Implikasinya langsung: kualitas ICL bergantung pada seberapa baik intuisi yang sudah dibangun selama training. Dan kalau intuisi itu bisa dirancang secara eksplisit, bukan dibiarkan terbentuk sendiri, mekanisme ini bisa diajarkan ke domain apapun, termasuk tabular data.
Kalau kualitas ICL bergantung pada intuisi awal model, pertanyaan berikutnya cukup jelas: bisakah kita mendefinisikan intuisi itu dari awal? Bukan menunggu model membangunnya sendiri, tapi merancangnya secara eksplisit sebelum training apapun dimulai.
Itulah yang dilakukan Prior-Data Fitted Networks (PFNs). Premisnya sederhana: kalau kita bisa mendefinisikan seperti apa “bentuk umum” dataset yang mungkin ditemui model, kita bisa membuat ribuan dataset tiruan dari bentuk itu, lalu melatih transformer untuk membuat prediksi yang tepat di atasnya.
Cara trainingnya seperti ini: untuk setiap dataset sintetis yang di-generate, sebagian dijadikan contoh yang dilihat model, sisanya jadi soal yang harus dijawab. Model belajar: dikasih data seperti ini, prediksi apa yang paling masuk akal? Proses ini diulang jutaan kali dengan dataset yang berbeda-beda, sampai model paham pola umumnya.
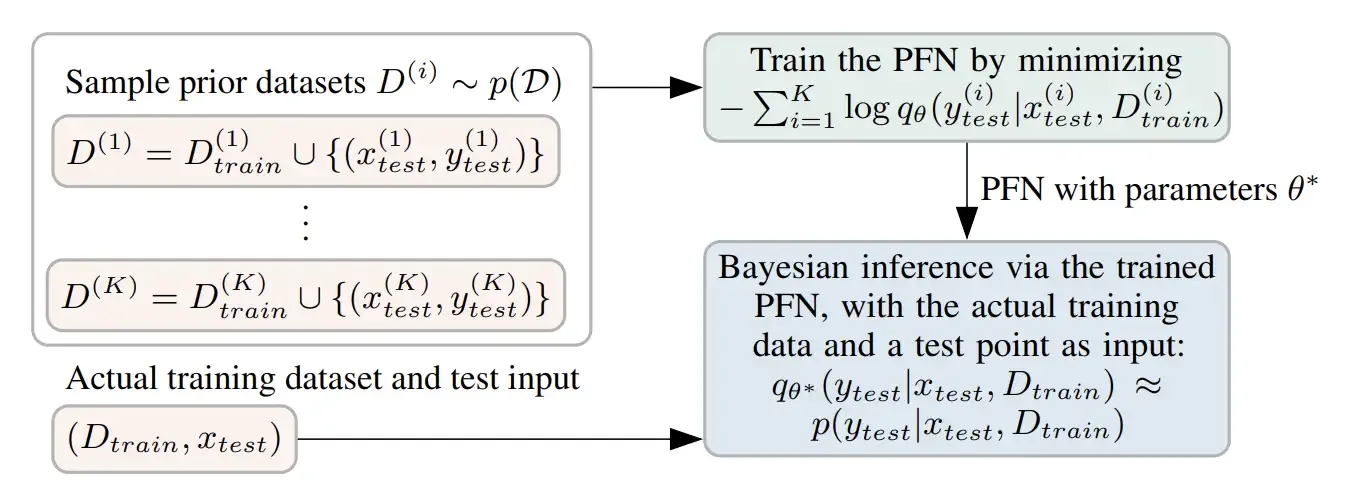
Train Sekali Di Data Sintetis, Prediksi Di Data Apapun. Sumber: Transformers Can Do Bayesian Inference (2022).
Hasilnya mengejutkan. Saat dikasih dataset nyata yang belum pernah dilihat sebelumnya, model bisa langsung membuat prediksi tanpa training ulang, persis seperti ICL di LLM, tapi kali ini untuk supervised learning.
Ini membuktikan sesuatu yang cukup penting: kita tidak butuh data nyata dalam jumlah besar untuk melatih model yang bagus. Selama data sintetisnya cukup representatif, model bisa belajar dari data buatan dan langsung bekerja di dunia nyata. Dan domain yang paling natural untuk dicoba pertama adalah data tabular, justru karena kita paling paham strukturnya.
PFN yang dirancang khusus untuk tabular data, itulah TabPFN. Paper pertamanya muncul di ICLR 2023, dan ini pertama kalinya framework PFN langsung diuji head-to-head melawan trees di domain tabular.
Prior TabPFN dirancang untuk meniru distribusi dataset yang mungkin ada di dunia nyata. Dua komponen utamanya adalah Bayesian Neural Networks dan Structural Causal Models. Yang terakhir bertugas memastikan dataset sintetis yang dihasilkan punya hubungan kausal yang masuk akal antar fitur, noise yang realistis, dan skala yang beragam. Prinsip yang dipegang: kalau ada dua penjelasan yang sama-sama masuk akal, yang lebih sederhana lebih diutamakan.
Training-nya dilakukan sekali: 12-layer Transformer dilatih selama 20 jam di 8 GPU. Setelah itu, model tidak pernah ditraining lagi. Kalau ada dataset baru, cukup masukkan data training sebagai konteks. Model langsung menjawab dalam satu forward pass, kurang dari satu detik.
Hasilnya di 18 dataset numerik dari OpenML-CC18 cukup mengejutkan. TabPFN mengalahkan XGBoost, LightGBM, dan CatBoost, dan setara dengan AutoML paling tangguh yang diberi waktu tuning satu jam, dengan selisih kecepatan yang besar: 230× di CPU dan 5.700× di GPU. Yang menarik, error TabPFN berkorelasi rendah dengan error tree-based models, artinya keduanya sering salah di tempat yang berbeda. Ketika digabung dalam ensemble, hasilnya lebih baik dari masing-masing.
Hasilnya juga divalidasi di 67 dataset tambahan dari OpenML dan konsisten. Semua kode dan model dirilis open source dengan antarmuka scikit-learn. Cukup fit dan predict. Responsnya dari komunitas beragam: sebagian langsung adopsi, sebagian skeptis karena angkanya terasa terlalu bagus.
Ada batasnya tentu. TabPFN v1 hanya bisa menangani maksimal 1.000 baris, 100 fitur numerik, dan 10 kelas, tanpa missing values dan fitur kategorikal. Di luar itu performanya turun. Tapi proof of concept-nya berhasil: transformer bisa belajar menjadi algoritma inferensi untuk tabular data dan mengalahkan trees. Dari sinilah istilah itu kemudian datang: tabular foundation model.
Dua tahun kemudian, versi keduanya keluar di Nature 2025. Nama yang sama, tapi skalanya jauh lebih besar. TabPFN v2 dilatih di sekitar 100 juta dataset sintetis selama dua minggu, dan kali ini bisa menangani data yang lebih berantakan: fitur kategorikal, missing values, outlier, serta regresi selain klasifikasi. Batasnya naik dari 1.000 ke 10.000 baris dan dari 100 ke 500 fitur.
Arsitekturnya juga berubah. V1 memperlakukan seluruh data sebagai satu urutan token. V2 punya mekanisme dual attention yang lebih eksplisit memanfaatkan struktur tabular: setiap sel attend ke fitur lain di baris yang sama untuk memahami konteks baris, lalu attend ke nilai yang sama di semua baris lain untuk memahami konteks kolom. Representasi setiap sel jadi kaya dari dua arah sekaligus. Satu keuntungan lain: kalau data training tidak berubah, hasilnya bisa di-cache dan tidak perlu dihitung ulang untuk setiap prediksi baru.
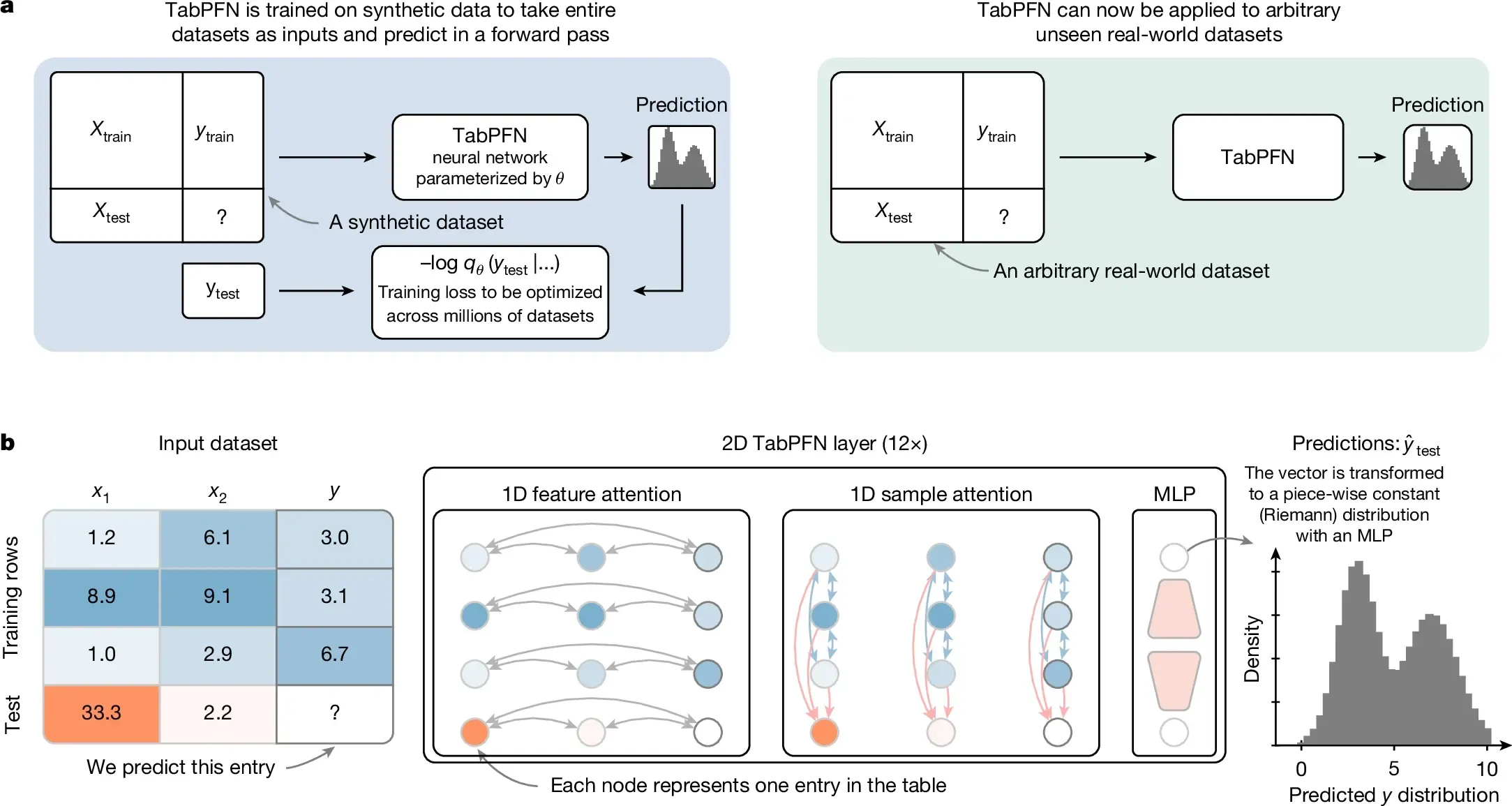
Arsitektur TabPFN v2: Setiap Sel Attend ke Baris dan Kolomnya. Sumber: Accurate predictions on small data with a tabular foundation model (2022).
Dalam 2,8 detik, TabPFN v2 mengalahkan CatBoost yang diberi waktu tuning 4 jam, dengan speedup 5.140× untuk klasifikasi dan 3.000× untuk regresi. Di paper inilah istilah itu dipakai secara resmi di judul untuk pertama kalinya: tabular foundation model.
Selain performa, v2 juga punya kemampuan yang sebelumnya tidak ada di model tabular manapun: bisa di-fine-tune, bisa menghasilkan data sintetis, bisa mengestimasi distribusi probabilitas, dan menghasilkan embedding yang bisa dipakai ulang.
Adopsinya terbilang cepat. Dalam 10 bulan, paper-nya dikutip hampir 400 kali dan paket open source-nya diunduh lebih dari 2 juta kali. Bidang medis jadi pengguna terbesar, lebih dari 50 aplikasi yang sudah dipublikasikan, dari diagnosis kanker hingga prediksi respons obat. Masuk akal: TabPFN memang sangat baik di dataset kecil, dan data medis memang jarang melimpah.
Versi terbarunya, TabPFN-2.5, dirilis November 2025 dengan kapasitas yang naik lagi, hingga 50.000 baris dan 2.000 fitur, 20 kali lebih besar dari v2. Ada satu detail menarik di pengembangannya: untuk mencari hyperparameter terbaik, mereka memakai TabPFN v2 sebagai surrogate model. Secara harfiah, TabPFN baru di-tune oleh TabPFN lama. Di dataset kecil sampai menengah (≤10.000 baris), win rate melawan XGBoost default mencapai 100%. Untuk dataset lebih besar hingga 100.000 baris, masih 87%. Kalau kecepatan inferensi jadi kendala, ada fitur distilasi yang mengubah TabPFN menjadi MLP atau tree ensemble biasa yang bisa langsung di-deploy.
Dulu, jawaban standar untuk mengalahkan trees di tabular data selalu soal arsitektur. Buat transformer yang lebih cocok untuk tabel, tambah regularisasi yang lebih cerdas, atau train di lebih banyak dataset tabular nyata. Pendekatan umumnya adalah memaksa neural network bekerja lebih baik di jenis data seperti ini.
TabPFN tidak melakukan satupun dari itu.
Model ini tidak pernah melihat satu pun dataset tabular nyata selama training. Seluruhnya dilakukan di data sintetis dari prior. Di inference time tidak ada gradient descent, tidak ada fitting. Model langsung menjawab dalam satu forward pass. Cara kerjanya lebih mirip melakukan inferensi dari pengalaman yang sudah terakumulasi, bukan belajar ulang dari nol setiap kali.
Yang juga tidak terduga adalah decision boundary-nya. Trees membuat keputusan dengan cara yang kaku. Satu fitur, satu threshold, lalu split, hasilnya prediksi yang berbentuk kotak-kotak di ruang fitur. TabPFN menghasilkan prediksi yang lebih halus, lebih terkalibrasi, dan lebih baik dalam menangkap ketidakpastian. Keduanya sering salah di tempat yang berbeda, dan itulah kenapa menggabungkannya dalam ensemble hasilnya lebih baik dari masing-masing.
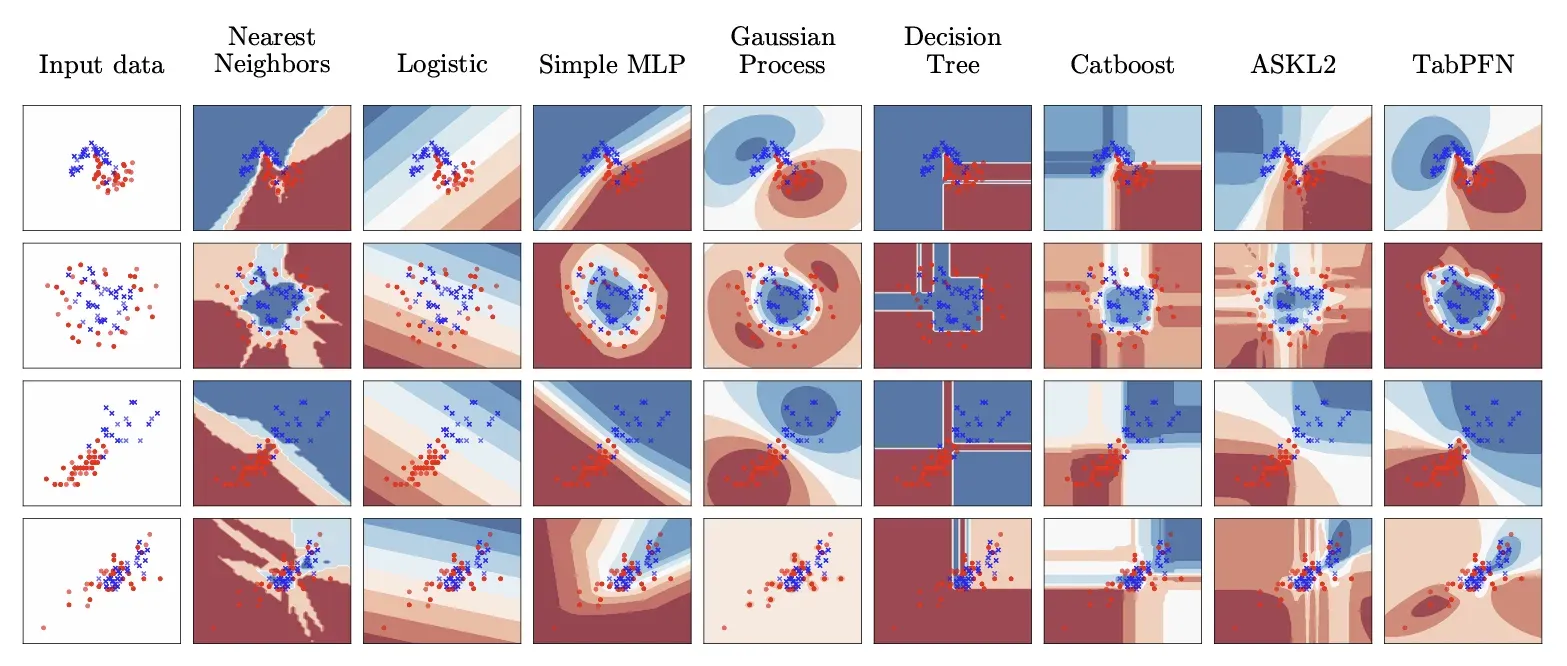
Decision Boundary Trees vs TabPFN: Kotak-Kotak vs Halus. Sumber: TabPFN A Transformer That Solves Small Tabular Classification Problems in a Second (2022).
TabPFN juga tidak mengandalkan skala. Tidak ada triliunan parameter, tidak ada dataset raksasa. Dengan transformer 12 layer yang dilatih 20 jam, TabPFN v1 sudah bisa mengalahkan AutoML yang diberi waktu tuning satu jam. Keberhasilannya bukan dari ukuran, tapi dari cara ia merepresentasikan masalah, dan dari prior yang cukup baik untuk menangkap keragaman tabular data di dunia nyata.
Dan mungkin itulah pelajaran yang paling tidak terduga dari cerita ini. Untuk domain yang strukturnya bisa kita definisikan dengan baik, kita tidak perlu menunggu data nyata dalam jumlah besar. Cukup definisikan priornya dengan benar, generate data sintetisnya, dan train model untuk melakukan inferensi di atasnya. Data nyata bukan satu-satunya jalan.
XGBoost tidak kemana-mana. Di dataset besar, di production dengan latency ketat, di kasus di mana interpretability adalah keharusan, trees masih pilihan yang wajar. TabPFN sendiri punya batasnya. “Trees always win” bukan lagi kenyataan absolut, tapi bukan berarti trees kalah.
Yang berubah adalah pertanyaannya. Dulu: arsitektur apa yang bisa mengalahkan trees di tabular data? Sekarang: prior seperti apa yang paling baik merepresentasikan distribusi dataset di domainmu? Itu pertanyaan yang lebih produktif, dan jauh lebih terbuka.
Ada perubahan yang lebih besar di balik ini. Selama puluhan tahun, kita mendesain algoritma ML secara eksplisit: tentukan arsitektur, pilih loss function, tune hyperparameter. TabPFN menunjukkan bahwa algoritma itu sendiri bisa dipelajari. Cukup definisikan seperti apa “dataset yang mungkin ada di dunia”, dan biarkan model belajar menjadi algoritma terbaik untuk distribusi itu.
Untuk praktisi, implikasinya cukup langsung. Kalau kamu bekerja dengan dataset kecil sampai menengah dan punya akses GPU, TabPFN layak dicoba sebelum langsung ke XGBoost. Bukan karena selalu lebih baik, tapi karena langsung bisa dipakai tanpa tuning, tidak perlu preprocessing khusus, dan hasilnya seringkali sudah sangat kompetitif. Error-nya juga berbeda dari trees, jadi kalau mau ensemble pun lebih mudah.
Dan untuk saya yang masih ngulik ini di tugas akhir, yang paling berkesan bukan hasil benchmarknya. Tapi menyadari bahwa pertanyaan sederhana “kenapa trees selalu menang?” ternyata membuka ke cara yang sama sekali berbeda dalam memikirkan machine learning.
- Why do tree-based models still outperform deep learning on typical tabular data?, Grinsztajn et al. (NeurIPS 2022)
- Deep Neural Networks and Tabular Data: A Survey, Borisov et al. (IEEE TNNLS 2024)
- Transformers Can Do Bayesian Inference, Müller et al. (ICLR 2022)
- TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second, Hollmann et al. (ICLR 2023)
- Accurate predictions on small data with a tabular foundation model, Hollmann et al. (Nature 2025)
- TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models, Grinsztajn et al. (arXiv 2025)